References and target systems
Global Metainfo#
Global metainfo objects were introduced with the Media Asset Management. Contents, belonging to a document, with no regard to its version or workflow, are saved within these objects.
This means that there is exactly one global metainfo object per document. This object is not subjected to versioning and can be processed in a workflow. The data of the associated document, however, is affected only indirectly. It can only be processed within a workflow.
The following meta information, if available, is stored in the global metainfo object:
__imperia_ac
__imperia_mam_unique
__imperia_asset_actions
__imperia_ac_variants
__imperia_ac_prevfile
__imperia_created
__imperia_mam_spool_original
__imperia_mime_content_length
__imperia_mime_content_type width height
__imperia_old_mdb_datatype
comment1
comment2
copyright
dpi
playlength
sellprice
server
viewprice
In addition, all fields listed in the system configuration variable GLOBAL_METAKEYS are included in the global Metainfo object.
If a document with edited global metainfo is imported, the metainfo in the document is overwritten. The exception is the meta field “template”.
When reparsing, the meta data values from the document are not transferred to the metainfo object and vice versa.
Important
The global meta information allows data to be changed after a workflow has finished and then the changes to be activated through reimport. This contradicts imperias philosophy that documents can be changed only within a workflow.
References#
A “reference” in imperia is an URL link within the meta data of a document that refers to another imperia document. For references to be captured and stored, it is necessary to know which document is available on which target system. Starting with imperia 11, the information about where a document is published or deleted will be recorded in detail.
Example: document A is created. During the Edit step, a link to an imperia document B is made via Linktool or iWE in document A. When the workflow is finished, the meta information of the referenced documents is saved in the meta field of the global metainfo of document A. In addition, this information is saved in a data table (SQLite table in File65). If the title or date of document B is changed, this will not affect document A.
If MAM assets are displaced, the paths to the respective assets will be updated and a document, containing references to these assets, will be republished. If the document is still in a workflow, the paths are adjusted, but the references are not directly updated, as this is done automatically on the next step.
If document B has to be deleted, the reference tables will be checked to see if another document contains a reference to document B. In case there is a reference to document B, it will not be deleted.
Important
You must keep in mind that links that do not point to physical files on disk will cause problems with the Link Consistency Check and the Category or Directory Restructuring, where broken links will be generated, without any warning.
Parsing References#
From imperia 11, references in a document will be checked at the end of a workflow (or by using the Finish plug-in). In this way the whole meta information of a document will be tested and references found in the global metainfo object and the reference tables will be taken.
Note
-
Since references are identified when a document is finished, referenced documents are not considered as such within a workflow.
-
When parsing, the meta information of a document is tested and not the meta information of the relevant copy pages.
All links in the meta information are taken into account during the check. Links, contained in a template, can only be checked with the “Link consistency check” and have no influence on the references. Only links to current or former imperia document will be included in the references. All other links are ignored and can be checked through the “Link consistency check”, if necessary.
Displaying References#
After determining references in a document, they will be displayed. The following options are possible:
-
to reimport the referenced document
-
contact the last editor and ask for the document to be regenerated
-
edit the document and reference a different document
In a deletion workflow the opposite functionality is needed. Through the plug-in, all documents that reference the current one are displayed. The following actions can be taken:
-
to import the referenced document
-
inform the last editor of the referenced document
-
not deleting the document, but republish it
Apart from the missing references, it is a good idea to check and display missing links in the plug-in. The link check is optional. While references are tested only on the basis of meta information, the link test is performed only on the basis of HTMLs.
Possible output
The document "On the Western Front" (/12/153/4553) references the following documents:
| Status | Action | |
|---|---|---|
| "Sun.jpg" (/15/223) | available | |
| "West.png" (/15/224) | available | |
| "news.pdf" (/16/77/1023) | deleted | 'import'/'mail' |
Because not all referenced documents are available, the document cannot be finished. Until all references are available, the document can be edited further and other objects can be chosen; or the deleted documents can be reactivated.
The link check of a document shows:
- for the site
/west/new/index.html.en
| Status | Action | |
|---|---|---|
| "/imprint.jpg" | not found | [] ignore |
- for the site
/westen/neu/index.html.de
| Status | Action | |
|---|---|---|
| "/imprint.jpg" | not found | [] ignore |
Removing References#
Note
References in imperia 11 can only be broken by the superuser.
Under “breaking a reference” the following is understood: a document uses an image (e.g. Hotel.jpg) and is published on a target system. Then the editor decides that the image is not suitable and wants to remove it from the site. He or she selects the corresponding image in the MAM and deletes it. In the dialog that follows that action, documents that use this image are displayed. If the editor still confirms the deletion, this will break all the links. In order to avoid that, only the superuser can break references in imperia 11.
What can be done?
In the case presented above, the best course of action is to import all documents that use the image in question and select a different image to use in its place.
What happens if a superuser breaks a reference?
Note
To better understand the process, it is necessary to know how imperia 11 detects references and what conditions have to be met.
A string is a valid reference when
- it looks like a path (/aa/bb);
- it is in a document's meta field;
- the path in the string leads to an existing document.
Thus, if the superuser breaks a reference to a document, the referenced object will be deleted. The string remains in the meta field of the document, where it has previously been used, but since the object does not exist anymore, the string is no longer a valid reference. The result is that after deleting an object, documents have no broken references.
Target Systems#
The meta information of the develop system is stored in the site/meta directory, as it was in imperia 8. However, from imperia 9, the meta information for target systems will be stored in the site/live directory, with a subdirectory created for each target system.
To understand the usage of target systems in imperia 11, the creation cycle of documents has to be carefully considered:
-
A document is created and finished in a workflow.
-
A file version (usually an HTML file) is created under the
HTDOCSdirectory and a binary file that contains the metadata is created insite/meta. -
When publishing to a target system, the two files (more than two with copy pages) are copied to the corresponding target systems.
The data in the first step is kept in the Archive. Since not all documents leave a workflow, the second step contains only part of the archived document. Furthermore, it is not necessary for all documents to be published on all target systems, so a target system may contain only a portion of the created documents.
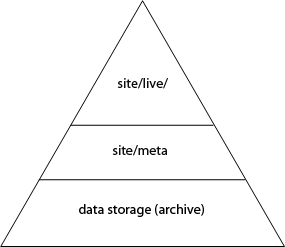
Conversely, it follows that documents that are available on the live system must also be available on the document system (as files under HTDOCS and site/meta). And documents on the develop system must also be available in data storage (i.e. the Archive).
The data, as write actions (files) and delete actions (notifications), is transferred to a target system through the publishing list. As a rule, imperia considers that all files are transferred to a target system. Exception is restricting the data through the publishing trigger.
Now, all entries are entered for each server. This concerns files writing as well as deletion. When a file is copied to a target system, the meta information to this document is written in site/live/N/. This is analogous for document deletion.
The publishing list is kind of a todo list that contains actions that must be performed to align a live system to a develop one.
Note
FOLLOWING WAS FIRST DECIDED BUT THEN REVISED: The editing of the publishing list, e.g. deleting of entries, is forbidden as the live and develop system wouldn't have the same state anymore and the references would become useless. THIS PROCESS IS NOW REVISED: IT IS POSSIBLE TO DELETE OR OVERWRITE 'DELETE'-ENTRIES IN THE PUBLISHING LIST.
Note
Delete entries, placed in the publish list are active for all live systems. This is why the deletion information about document's variants, subjected to deletion on each server, is contained in the global metainfo object of a document.
If the publishing list is processed completely, there is no document on a live system, that does not exist on the develop one and there is no document on the develop system, that is not in the data storage.
Note
The only exception is the time domain until the publishing list executes the write and delete operations. During this execution, there may be documents that have been deleted from a develop system, but are still pending deletion on a live system.
These principles are the basis for consistent references in a system. From these principles, the following implications for deleting documents are available:
-
A document can be deleted from a data storage (incl. the Archive) only if this document is deleted from the develop system (as file under
HTDOCSandsite/meta). -
A document can only be deleted from a develop system if this document is also deleted from all live systems (as file under
HTDOCSandsite/meta). -
So that the last point can be ensured, a publishing trigger should never be applied to the deletion action. Otherwise, a publishing trigger could prevent the publishing of a deleted statement and a live system would include more data than the develop system or the data storage, which may not be the intention of the references. For this reason, the publishing trigger ignores delete instructions in a publishing list.
With separate target systems, e.g. managing documents through publishing triggers, imperia considers that the same versions of documents are transferred on the target systems. The different versions on the live systems give a reference error. This deviation from the standard can be accepted for projects, but it should be clear that the references won't work with their full range.
Restoring a Target System#
OPTIONAL FUNCTION
imperia 11 provides the possibility to restore the state of a live system, in which one publishes all documents in /site/live/N/, ignoring the transfer cache.
There are two variants for restoration. 1. Republishing the existing HTML pages based on the documents under /site/live/N/. 2. Reparse the existing documents in /site/live/N/.
Publishing Exapmples#
Example 1:
A document with a NodeID /1 generated in the language variants DE and EN, results in the files /index.html.de and /index.html.en on the file system under HTDOCS. At the same time, in the publishing list, an entry is created for each file that this document is to write (W) on the target system.
| NodeID | File name | Language versions | Publishing list |
|---|---|---|---|
| /1 | /index.html | DE EN | /1:W:/index.html.de/1:W:/index.html.en |
A second document with the NodeID /2 will only be created in EN language version. It generates a /index.html.en file in the file system under HTDOCS. This has now overwritten the created document /1 version. So the English version of document /2 is overwritten in the publishing list. The file /index.html.de will not be changed in the file system and also the entry in the publishing list remains.
| NodeID | File name | Language versions | Publishing list |
|---|---|---|---|
| /2 | /index.html | EN | /1:W:/index.html.de /2:W:/index.html.en*x) |
The publishing is triggered. The files /index.html.de (based on document /1) and /index.html.en (based on document /2) will be published.
| NodeID | File name | Language versions | Publishing list |
|---|---|---|---|
Publishing <blank>
Now, document /1 is reimported and finished without modifications. It created the /index.html.de and /index.html.en files in the file system. These will be entered exactly in the publishing list.
| NodeID | File name | Language versions | Publishing list |
|---|---|---|---|
| /1 | /index.html | DE EN | /1:W:/index.html.de/1:W:/index.html.en*x) |
The documents not published at once and document /1 is processed once again, whereupon the EN version is removed. Upon finishing the document, only the DE version of the document is transferred to the file system. The English page is deleted from the file system. The German file is added to the publishing list to be written and the English one to be deleted.
| NodeID | File name | Language versions | Publishing list |
|---|---|---|---|
| /1 | /index.html | DE | /1:W:/index.html.de/1:D:/index.html.en |
Publishing is triggered. The /index.html.de file (based on document /1) is written and the /index.html.en file (based on document /2) will be deleted. At the same time, the same is done on the develop system.
| NodeID | File name | Language versions | Publishing list |
|---|---|---|---|
| Publishing |
Example 2:
A document with a NodeID /1 generated in the language variants DE and EN, results in the /index.html.de and /index.html.en files in the file system under HTDOCS. At the same time, in the publishing list, an entry is created for each file that this document is to write (W) on the target system.
| NodeID | File name | Language versions | Publishing list |
|---|---|---|---|
| /1 | /index.html | DE EN | /1:W:/index.html.de/1:W:/index.html.en |
Again, a second document with NodeID /2 is generated only in English. It generates a /index.html.en file in the file system under HTDOCS. This has now overwritten the created document /1 version. So the English version of document /2 is overwritten in the publishing list. The file /index.html.de will not be changed in the file system and also the entry in the publishing list remains.
| NodeID | File name | Language versions | Publishing list |
|---|---|---|---|
| /2 | /index.html | EN | /1:W:/index.html.de/2:W:/index.html.en*x) |
Publishing is triggered. The files /index.html.de (based on document /1) and /index.html.en (based on document /2) will be published.
| NodeID | File name | Language versions | Publishing list |
|---|---|---|---|
| Publishing | <blank> |
Now, document /1 is reimported and the English version is removed. At the end, the file /index.html.de is generated and it will be entered in the publishing list to be written (W). The English file has been deleted and it has to be entered for deletion in the publishing list.
| NodeID | File name | Language versions | Publishing list |
|---|---|---|---|
| /1 | /index.html | DE | /1:W:/index.html.de [/2:W:/index.html.en]skipped*x) |
SUGGESTION
-
Set a system configuration variable, such as
STRICT_PATHS. If this variable is set totrue, a warning is always written to the log file when a document with another NodeID overwrites an existing URL (all *x). -
Systems in which individual pages (e.g. the homepage) are always re-created, should then work with the DocSelector and again edit old versions of the document (this keeps the number of versions of documents smaller).
-
The advantage is that when something is to be overwritten, there will be a warning.